대규모 언어 모델(LLM)의 빠른 발전은 대화형 AI 시스템의 개발을 가속화하고 있습니다. 그러나 이러한 모델의 성능을 실제 챗봇 시나리오에서 평가하는 것은 여전히 큰 도전입니다.
무류사용으로 실제 챗봇 상호작용을 시뮬레이션하여 다양한 대규모 언어 모델들의 성능을 평가하고 비교해 보시기 바랍니다.

목차
LMSYS Chatbot Arena: Benchmarking LLMs in the Wild 이란?
LMSYS Chatbot Arena: Benchmarking LLMs in the Wild (실제 LLM 벤치마킹)
https://chat.lmsys.org/ URL 선택 후 들어가면 아래와 같이 경고 메시지가 나타남

LMSYS Chatbot Arena는 대규모 언어 모델(LLM)의 실 세계 대화 시나리오에서의 성능을 벤치마킹하고 평가하는 플랫폼입니다.
개발자, 연구자, 사용자는 이 플랫폼을 통해 다양한 LLM의 기능을 테스트하고 비교할 수 있습니다.
LMSYS Chatbot Arena 주요 기능
대화 시나리오: 플랫폼은 실제 세계 대화와 유사한 다양한 시나리오를 제공합니다. 예를 들어 고객 서비스, 기술 지원, 대화 등이 있습니다.

LLM 통합: LMSYS Chatbot Arena는 다양한 LLM, 예를 들어 BERT, RoBERTa, DistilBERT와 같은 모델을 지원합니다.
평가 지표: 플랫폼은 LLM의 성능을 평가하는 다양한 지표를 제공합니다. 예를 들어 응답 정확도, 유창성, 일관성, 참여도 등이 있습니다.
사용자 정의: 사용자는 대화 시나리오, 평가 지표, LLM을 자신의 특정 요구에 맞게 조정할 수 있습니다. :
LMSYS Chatbot Arena 사용 방법
다음은 LMSYS Chatbot Arena를 사용하는 단계별 가이드입니다.
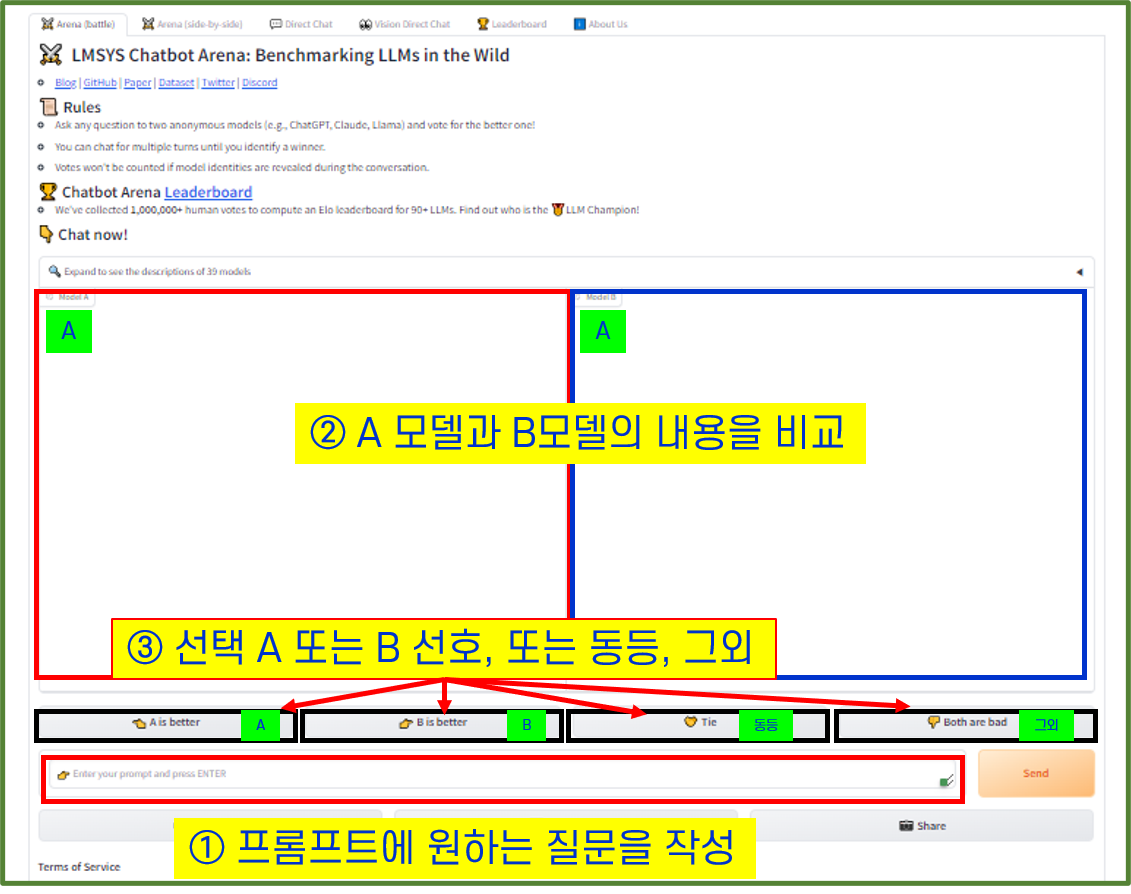
- 계정 생성: LMSYS Chatbot Arena 웹사이트에 계정을 생성하세요.
- 시나리오 선택: 미리 정의된 시나리오 하나를 선택하거나 새로운 질문을 생성하세요.
- LLM 선택: 테스트할 LLM을 선택하세요.
- 평가 지표 설정: 평가 지표를 자신의 요구에 맞게 설정하세요.
- 실험 실행: 선택한 시나리오, LLM, 평가 지표와 함께 실험을 실행하세요.
- 결과 분석: LLM의 성능을 평가하는 평가 지표와 응답 출력을 검토하세요.
- 결과 비교: 다양한 LLM 또는 동일한 모델의 반복을 비교하세요.
- 개선 및 반복: 얻은 통찰을 바탕으로 LLM을 개선하거나 대화 시나리오, 평가 지표를 조정하세요.
Expand to see the descriptions of 39 models
Expand to see the descriptions of 39 models을 을 선택하고 들어가면 다양한 AI 모델이 있습니다

| Claude: Claude by Anthropic | Reka Core: Frontier Multimodal Language Model by Reka | Qwen Max: The Frontier Qwen Model by Alibaba |
| Qwen 1.5: The First 100B+ Model of the Qwen1.5 Series | Llama 3: Open foundation and chat models by Meta | Gemini: Gemini by Google |
| Snowflake Arctic Instruct: Dense-MoE transformer by Snowflake AI | Phi-3: A capable and cost-effective small language models (SLMs) by Microsoft | Mixtral of experts: A Mixture-of-Experts model by Mistral AI |
| GPT-4-Turbo: GPT-4-Turbo by OpenAI | GPT-3.5: GPT-3.5-Turbo by OpenAI | Reka Flash: Multimodal model by Reka |
| Command-R-Plus: Command-R Plus by Cohere | Command-R: Command-R by Cohere | Gemma: Gemma by Google |
| Zephyr 141B-A35B: ORPO fine-tuned of Mixtral-8x22B-v0.1 | DBRX Instruct: DBRX by Databricks Mosaic AI | Llama 2: Open foundation and fine-tuned chat models by Meta |
| OLMo-7B: OLMo by Allen AI | Vicuna: A chat assistant fine-tuned on user-shared conversations by LMSYS | Yi-Chat: A large language model by 01 AI |
| Code Llama: Open foundation models for code by Meta | OpenHermes-2.5-Mistral-7B: A mistral-based model fine-tuned on 1M GPT-4 outputs |
다양한 AI 모델을 선택하여 모델별 비교하여 보시기 바랍니다
질문과 결과물 비교 후 LLM 모델 선택
시나리오 선택: 미리 정의된 시나리오 하나를 선택하거나 새로운 질문을 생성하세요.
아래와 같이 LMSYS Chatbot Arena: Benchmarking LLMs in the Wild에 대해 소개와 함께 사용방법을 알려달라고 주문함

LMSYS Chatbot Arena: Benchmarking LLMs in the Wild에 대해 소개와 사용방법에 대해 2개의 모델에서 결과를 작성함
결과물에 대해 아래 LLM 선택에서 A 모델이 좋다고 생각하고 A모델을 선택합니다
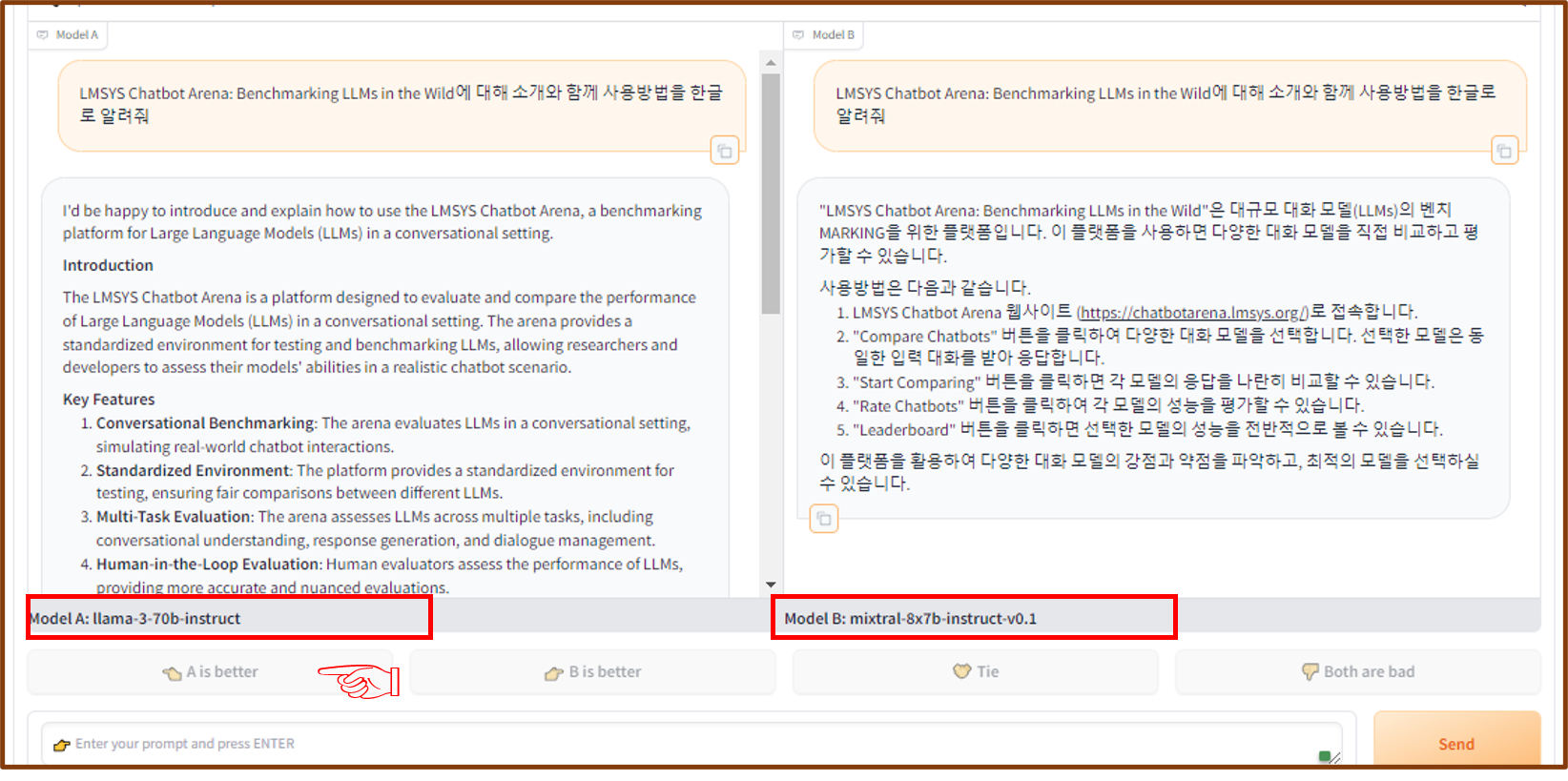
A와 B 모델에 대한 모델명을 알려줌 A모델 (llama-3-70b-instruct) / B모델 (mixtral-8x7 b-instruct-v0.1)로 알려줌으로
모델을 비교할 수 있습니다.
결론
LMSYS 챗봇 아레나는 객관적이고 공정한 평가 기준을 제공하여, 사용자들은 다양한 대화 모델을 비교하고 선택할 수 있습니다.
이 플랫폼을 활용하여 최적의 모델을 선택하고, 개선점을 파악하여 더욱 발전하는 대화 모델 개발을 지원할 수 있습니다. 따라서 현재 다양한 대화 모델을 비교할 수 있습니다. 적극 활용 하시기 바랍니다.
프롬프트 엔지니어링
프롬프트 엔지니어링: AI 언어 모델의 정확한 답변을 위한 핵심 전략
프롬프트 엔지니어링: AI 언어 모델의 정확한 답변을 위한 핵심 전략
인공지능 언어 모델은 우리의 일상 생활에서 점점 더 중요한 역할을 하고 있습니다. 그러나 이러한 모델은 정확한 답변을 제공하기 위해 적절한 프롬프트를 필요로 합니다. 따라서 프롬프트 엔
the-see.tistory.com
'IT&Tech' 카테고리의 다른 글
| "ytlarge.com: 유튜브 수익 창출 상태를 쉽게 확인하는 방법!" (7) | 2024.06.07 |
|---|---|
| AI 생성물 워터마크 표시 의무화 등 새로운 디지털 질서 정립 추진계획 (1) | 2024.05.21 |
| 동영상 생성 AI 'Sora'(소라) 새로운 창작 시대의 서막 (2) | 2024.04.20 |
| 새로운 음악 생성 AI, Udio 사용방법 알아보기 (0) | 2024.04.14 |
| AI 기술 혁신 및 일상화를 위한 정부의 전략적 투자 (0) | 2024.04.04 |



